
Wie schnell kann ich Ergebnisse im A/B- oder multivariaten Test erhalten und kann ich mich auf diese Ergebnisse verlassen? Diese grundlegenden Fragen stellen sich die meisten Seitenbetreiber, wenn sie mit der kontinuierlichen Optimierung ihrer Website beginnen.
Früher war die Verbesserung einer Website in weiten Teilen eine Frage des Geschmacks. Heute bestimmen Statistik und Mathematik, an welchen Stellschrauben einer Website gedreht wird.
A/B-Testing ist bereits etablierter Standard zur kontinuierlichen Optimierung von Websites. Dabei werden der ursprünglichen Version des zu testenden Elements eine oder mehrere Varianten gegenüber gestellt. Besucher sehen während des Testzeitraums entweder die Ursprungsversion oder eine Variante. Anhand ihres Verhaltens wird dann die bessere Version ausgewählt. Der multivariate Test betrachtet die gleichzeitige Veränderung mehrerer Elemente auf einer Seite.
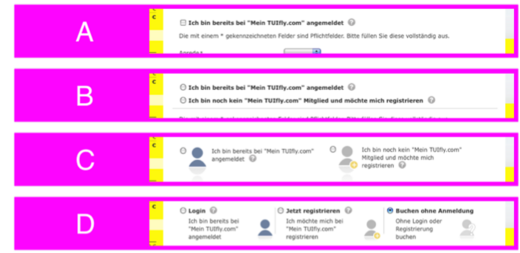 Ursprungsversion und vier Varianten eines A/B-Tests für TUIfly.com
Ursprungsversion und vier Varianten eines A/B-Tests für TUIfly.com
Diese Methode wird auf dem gesamten Weg des Konsumenten (Customer Journey) auf einer Website verwendet: von der Akquisition der Besucher über Landingpages bis hin zur detaillierten Optimierung. Insbesondere in der Akquisitionsstrecke sind dabei schnelle Ergebnisse gefragt, um mit hoher Sicherheit die beste Version auszuwählen.
Um das zu schaffen, wird vorab häufig kein fixer Test-Zeitraum bestimmt. Vielmehr wird durch kontinuierliches Monitoring der aktuellen Testergebnisse der Zeitpunkt abgewartet, an dem eine Variante vermeintlich besser funktioniert als die andere.
Zu Beginn des Tests ist ein Ziel festgelegt worden, z.B. der Kauf eines Produkts, die Anmeldung zum Newsletter oder einfach das Erreichen einer bestimmten Seite. Sind die Daten erst einmal gesammelt, ist die beste Version schnell bestimmt.
Viel wichtiger, als die bessere Version zu finden, ist allerdings, sicherzustellen, dass das Ergebnis statistisch signifikant ist, also nicht durch einen Zufall entstanden ist. Schlimmstenfalls könnte sonst ein Sieger gekürt werden, wo es keinen gibt, oder gar die falsche Seiten-Variante zum Sieger erklärt worden.
Statistische Signifikanz ist keine neue Methode, die spezifisch für den Bereich des A/B-Testings entwickelt wurde, sondern ist ein erprobtes Mittel, um den Zufall auszuschließen.
Für die Berechnung der Signifikanz gibt es verschiedene, etablierte Methoden, wie z.B. den T-Test Chi^2-Test. Diese Methoden prüfen anhand der Zahl der Testteilnehmer, der bisherigen und der im Test erzielten Zielerreichung (Conversion Rate) und der getesteten Varianten, ob die Verteilung der Ergebnisse zufällig ist oder nicht. Im Netz gibt es verschiedene Signifikanz- und Confidenz-Rechner, mit deren Hilfe man eigene Tests bewerten kann.
Noch einfacher werden Tests und die Berechnung der Signifikanz heute mit dem Einsatz entsprechender Tools, wie z.B. Google Website Optimizer oder Adobe Test & Target. Diese Tools helfen bei der Durchführung von A/B- und multivariaten Tests und werten diese statistisch aus.
In der kontinuierlichen Optimierung sollten sich Seitenbetreiber nicht zu schnellen Entscheidungen aufgrund vermeintlich klarer Testergebnisse verführen lassen. Vielmehr muss jedes Testergebnis auf statistisch signifikanten Daten aufbauen. Nur so kann sichergestellt werden, dass Entscheidungen auf relevanten Ergebnissen basieren und die Website mit jeder Optimierung besser wird.
Data Love
Es gibt 28 Beiträge in Data Love.
Wer braucht schon digitale Privatsphäre?
Wir steuern auf einen neuen Generationenkonflikt zu, und es ist eine neue Variante des Konflikts zwischen digitalen Eingeborenen und Einwanderern. Diesmal geht es um die Privatsphäre und ob es sie im digitalen Zeitalter überhaupt noch geben kann.
Nein, meint eine neue Gruppe, die sich datenschutzkritische Spackeria nennt. In einem Interview mit dem Spiegel, der die Spackeria grob als „Internet-Exhibitionisten“ tituliert, sagt die 25-jährige Julia Schramm Sätze wie diesen:
Meine Daten können mir nicht mehr gehören. Wir haben längst die Kontrolle darüber verloren. Ob wir es nun gut finden oder nicht: Privatsphäre ist sowas von Eighties. (lacht)
Mich deuchte ja schon länger, spätestens eigentlich seit dem Auftritt von Peter Schaar auf der re:publica, dass Datenschutz sowas von Eighties ist. Privatsphäre jedoch hielt ich bislang für durchaus wünschenswert. Aber das mag am Alter liegen, schließlich bin ich digitaler Immigrant, dessen Aufenthaltserlaubnis für das Internet seit 1994 immer nur jährlich verlängert wird.
Julia Schramm gehört der gleichen Generation an wie Mark Zuckerberg. Und so wie Zuckerberg mit Facebook die praktischen Grundlagen des sozialen Miteinanders im digitalen Raum neu definiert, so definiert Schramm die theoretischen Grundlagen um.
Vieles spricht tatsächlich für den radikalen Abschied von der Privatsphäre. Allerdings, so merkt Johan Staël von Holstein nicht ganz zu Unrecht an, ist das auch eine Frage des Alters. Wer erst einmal Kinder hat und es zu einem gewissen Wohlstand gebracht hat, der legt womöglich mehr Wert darauf, seine sensiblen Daten zu schützen, als ein College-Student.
Johan Staël von Holstein arbeitet an einem Facebook-Herausforderer namens MyCube. Er will damit den Nutzern die Kontrolle über ihre Daten zurückgeben, also das schaffen, was Julia Schramm für unmöglich hält. Auf der NEXT11 im Mai wird er sprechen. Tickets gibt es hier.
Was ist Data Love?
Die NEXT11 (Termin vormerken: 17./18. Mai, Tickets gibt es hier) steht unter dem Motto Data Love. Aber was heißt das eigentlich?
Diese Frage stellte Alexander Franz Köllner von IFRANZNATION am vergangenen Wochenende auf dem Videocamp im schönen Essen. Hier die Antworten, im Video, versteht sich:
Vgl. auch: The Principles of Data Love
Stephan Noller, die Liebe zu Daten und der digitale Mob
Wir leben in einem seltsamen Land. In diesem Land kann sich die Öffentlichkeit tagelang an der Dissertation eines Ministers abarbeiten, können belastende Daten über Plagiatsvorwürfe in einem öffentlich zugänglichen Wiki gesammelt und ausgewertet werden.
In diesem Land können kleine Volksaufstände gegen die sogenannte Datensammelwut von Unternehmen wie Google und Dienste wie Street View enstehen – und das gleiche Volk nachher zu den intensivsten Nutzern des Straßenbilderdienstes gehören. In diesem Land können Konsumenten mit Begeisterung jede Menge werbefinanzierte Dienste nutzen und gleichzeitig gegen Werbung sein.
Ist das nicht schizophren?
Stephan Noller hat sich jüngst in der Zeit zu seiner, ich möchte fast sagen, Liebe zu Daten bekannt.
Ich finde die aktuelle Debatte über Datenmissbrauch im Internet ärgerlich. Nicht nur, weil ich Teil dieser Industrie bin. Sondern vor allem, weil darin eine gewisse Technologiefeindlichkeit und auch Ignoranz mitschwingt. Es wird der Eindruck einer im halblegalen Bereich operierenden, auf kurzfristige Gewinne ausgerichteten Industrie erweckt, die nur so viele Bedenken kennt, wie Rechtsanwälte und Verbraucherschützer ihr jeweils abtrotzen können.
Technologiefeindlich ist die Sichtweise, weil Tracking sehr nah am Kern dessen operiert, was das Internet so faszinierend und nützlich macht und es bereits jetzt zu einem der stärksten Wachstumsfaktoren in mehreren Wirtschaftsbereichen hat werden lassen. Ignorant ist die Haltung, weil das Internet uns eine völlig neue Welt eröffnet.
Wie um Stephan Nollers Diagnose zu bestätigen, schlägt sich in den Kommentarspalten unter seinem Artikel der digitale Mob nieder, der Werbung im Allgemeinen und Targeting im Besonderen zwar für Teufelszeug hält, aber selbstverständlich nicht auf allerlei dadurch finanzierte digitale Annehmlichkeiten verzichten will. Diese Debatte wird in Deutschland leider auf einem nachgerade unterirdischen Niveau geführt. Ein wenig Dave Winer könnte nicht schaden:
Advertising will get more and more targeted until it disappears, because perfectly targeted advertising is just information. And that’s good!
True Data Love: KLM Surprise
Die königliche Fluglinie der Niederlande hat mit einer kleinen Social-Media-Kampagne ihre netzaffinen Kunden überrascht. Die Mechanik war einfach und beruhte auf Foursquare: Wer bei Foursquare eincheckt, so die Annahme, der hat auch ein Profil bei Facebook, Twitter oder LinkedIn.
Daraus lassen sich öffentlich zugängliche Informationen über den Fluggast und den Grund seiner Reise gewinnen. Das Social-Media-Team überraschte die KLM-Passagiere dann mit einem kleinen, persönlichen Geschenk. Das Ganze war dann auf Facebook zu sehen.
Aus den Kommentaren bei YouTube lässt sich auch gleich das Risiko einer solchen Kampagne ersehen: Auch unzufriedene Passagiere melden sich zu Wort. Ein persönliches Geschenk tröstet nicht über Unzulänglichkeiten bei der eigentlichen Dienstleistung hinweg.
Auf jeden Fall aber ist die Kampagne ein schöner Fall von Data Love. So lautet das Motto der NEXT11. KLM zeigt hier beispielthaft, wie aus dem stetig wachsenden Datenstrom neue Anwendungen mit Mehrwert für den Konsumenten entwickelt werden können.
[Hat tip to @pr_ip]
Datenschutz: Ilse Aigner und der digitale Radiergummi
Die Idee ist bestechend: Bilder im Internet sollen ein Verfallsdatum bekommen oder vom Nutzer nicht nur publiziert, sondern auch wieder gelöscht werden können. Doch ein tragfähiges Konzept, wie diese Idee in die Praxis umzusetzen wäre, hat bis jetzt noch niemand vorlegen können.
Verbraucherschutzministerin Ilse Aigner hat sich diese Idee und ein ganz konkretes Konzept nebst fast fertiger Softwareimplementierung zu eigen gemacht. Die Software heißt X-Pire, entwickelt hat sie Informatikprofessor Michael Backes. Bei einer Ministeriumsveranstaltung durfte er heute seine Lösung präsentieren.
Das Echo ist eher verhalten. Bitte vergessen, lautet das Fazit von Jürgen Schmidt, Chefredakteur heise Security. Zum Vergessen, meint fast gleichlautend netzpolitik.org. Kristian Köhntopp lenkte schon vor einer Woche die Aufmerksamkeit auf die zentrale Schwäche des Konzepts:
Was ist X-Pire?
Ein Firefox-Plugin für ein proprietäres Bildformat, das kryptographisch signierte Bilder nach einem bestimmten Datum nicht mehr anzeigt. Was natürlich auch circa 3 Millionen Weisen leicht auszutricksen ist, und in keiner Weise einem Radiergummi entspricht.
Noch dazu ist X-Pire ein ausgezeichnetes Ausforschungsinstrument, das sich gegen die Privatsphäre derjenigen Benutzer richtet, die das Plugin tatsächlich installieren.
Durch das Runterladen des Schlüssels vom Keyserver bekommt der Betreiber des Keyservers ausgezeichnete Analytics-Daten darüber, welcher Benutzer wann welches Bild angesehen hat – wie können Sie eine solche Praxis gutheißen, Frau Aigner?
Beim Thema Datenschutz beschleicht mich häufig das Gefühl, eine Debatte zu erleben, die nicht ganz auf der Höhe der Zeit ist. Ein Meilenstein war sicherlich das Volkszählungsurteil des Bundesverfassungsgerichts von 1983. Doch seitdem sind bald 30 Jahre vergangen.
Schon gut zehn Jahre nach dem wegweisenden Urteil erschien das Web auf der Bildfläche. Angesichts der damit verbundenen neuen Herausforderungen wurde das Thema Datenschutz bereits damals neu diskutiert, allerdings ohne wirkliche Lösung. Konzepte wie X-Pire sind keineswegs neu, konnten sich aber aus vielen guten Gründen nicht durchsetzen.
Die Bundesregierung hat sich im Koalitionsvertrag die Aufgabe gegeben, das Bundesdatenschutzgesetz ans Internetzeitalter anzupassen. Dass hier dicke Bretter zu bohren sind, weiß auch Ilse Aigner.
Fragen an die Ministerin gibt es also genug. Warum nicht auf großer Bühne bei der NEXT11 mit ihr diskutieren? Hier der Vorschlag, bitte abstimmen!
Neun Prognosen für 2011
Mit meinen Prognosen für das neue Jahr bin ich traditionell spät dran. Was steht an für 2011?
- Die Generation Internet bleibt auch in diesem Jahr draußen vor der Tür. Die Geburtsjahrgänge ab 1991 sind zahlenmäßig zu schwach, um sich in einer alternden Gesellschaft durchzusetzen, in der Rentner, Pensionäre und Sozialleistungsempfänger den Ton angeben.
- Das Leistungsschutzrecht für verlegerische Leistungen, bereits 2009 im Koalitionsvertrag von CDU/CSU und FDP verankert, steht auch 2011 noch auf der Agenda, Mario Sixtus zum Trotz.
- Datenschutz und digitale Privatsphäre sind das große Thema des Jahres. Eine neue Generation von Start-ups wie MyCube und Personal bringt konstruktive Lösungen für das Dilemma zwischen digitaler Privatsphäre und Social (the animal formerly known as Social Media).
- Das nächste Buch von Jeff Jarvis (Public Parts) gibt dieser Debatte erst richtig Schwung. Es erscheint in diesem Jahr, die deutsche Ausgabe wird unter dem Titel Das Deutsche Paradoxon publiziert.
- Der Werbemarkt wächst auch 2011 leicht. Die Gewinner sind Online- und TV-Werbung, nicht zuletzt wegen der zunehmenden Konvergenz ihrer Technologien.
- Apple TV bekommt noch in diesem Jahr einen App Store. Damit überträgt Steve Jobs das Erfolgsmodell von iTunes, iPhone, iPad und Mac App Store auf das Fernsehen. Google TV nimmt einen zweiten Anlauf im Weihnachtsgeschäft 2011.
- Das App-Fieber des vergangenen Jahres klingt weiter ab, aber das neue Paradigma setzt sich durch. Mac App Store, Chrome OS – alles wird App. Sogar Microsoft kündigt einen App Store für Windows an, der aber nicht vor 2013 starten wird.
- Das digitale Buch hebt endgültig ab. Amazon bringt den Kindle Store nach Deutschland, Google Books lässt noch auf sich warten, die Sortimente der übrigen Anbieter werden größer.
- Facebook geht 2011 an die Börse. Der Börsengang schlägt alles, was im digitalen Bereich bis jetzt da war. Es ist ein Meilenstein wie die IPOs von Netscape und Google.
Was meinen Sie? Welche Themen bestimmen das Jahr 2011?
Careless Computing? Richard Stallman und die Cloud
Die Wahrheit liegt in den Daten. Und wenn die Daten abheben und in die Wolken des Internets verschwinden, dann liegt die Wahrheit eben in den Wolken. Doch wer hat dann die Kontrolle?
Der säkulare Trend ist klar: weg vom lokalen Rechner, hin in die Datenzentren der großen Akteure wie Google und Amazon. Heißt das auch: weg aus der direkten Kontrolle des Nutzers, hin zur Kontrolle durch internationale Konzerne?

Richard Stallman. Photo by jeanbaptisteparis on Flickr. Some rights reserved
Richard Stallman ist ein Unikum. Bereits in den 80er Jahren gründete er die Free Software Foundation und setzt sich seitdem für freie Software ein, was nicht unbedingt auch kostenlose Software bedeutet. Das wohl bekannteste und bedeutendste Beispiel für freie Software ist Linux.
Auf Linux basiert das neue, von Google entwickelte Betriebssystem Chrome OS, das vor kurzem auf ersten Testrechnern ausgeliefert wurde. Es gibt auch eine freie Variante namens Chromium, doch mit freier Software hat das Unterfangen nicht viel zu tun.
Das meint jedenfalls Richard Stallman, der den polemischen Begriff Careless Computing ins Spiel gebracht hat. Für Stallman sieht Chrome OS wie ein Plan aus, der die Nutzer zu Careless Computing verführen soll, indem sie gezwungen werden, ihre Daten in der Cloud abzulegen statt auf den eigenen Rechnern. In den USA, so sein Argument, verlieren die Nutzer sogar die gesetzlichen Rechte an ihren eigenen Daten, wenn sie diese auf den Systemen von Unternehmen ablegen.
Sollten wir also unsere Daten der Cloud anvertrauen? Oder sollten vielleicht eher die Gesetze geändert werden, um sie der neuen Situation anzupassen?
Sie möchten Richard Stallman gerne auf der Bühne der NEXT Conference im Mai 2011 sehen? Der Call for Participation ist offen, Sie können hier abstimmen.