
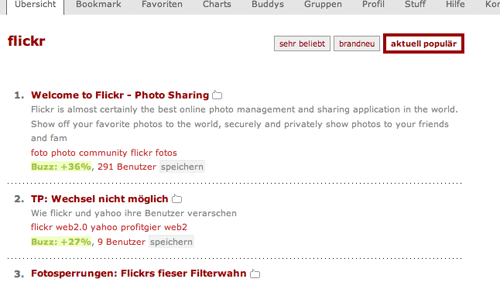
Der Social-Bookmarking-Dienst Mister Wong präsentiert ein interessantes neues Feature: Wer nach Tags sucht, bekommt jetzt die Möglichkeit, die „aktuell populären“ Bookmarks aufzulisten. Sortiert wird nach einem „Buzz-Faktor“, der anzeigt, wie die Popularität einer Website ansteigt. Richtig spannend wird’s, wenn die Zahl der Bookmarks noch weiter wächst und Mister Wong nicht nur bei den absoluten Top-Themen eine größere Auswahl an aktuellen Bookmarks präsentieren kann — dann könnte das Feature eine echte Konkurrenz für Technorati & Co. werden.
Suchmaschinen
Es gibt 2 Beiträge mit dem Schlagwort Suchmaschinen.
Blogsuchmaschinen
Christopher Laux‘
Motivation zur Arbeit an einer eigenen Suchmaschine für Blogs stammt
aus der Unzufriedenheit mit der Qualität von Blogsuchmaschinen: Die
Ergebnisse von Suchen innerhalb von Blogs waren über Dienste wie
Technorati oder die Blogsuche von Google oder Yahoo nicht zu
erreichen. Beim Barcamp Berlin diskutierte er seine Erfahrungen bei
den ersten Schritten, eine eigene Blogsuchmaschine zu bauen.
Die Maschine funktioniert so: Während ein „Spider“ Blogs findet, hat ein
„Visitor“ die Aufgabe, aktuelle Einträge zu finden. Diese beiden
Elemente sind bereits implementiert. Noch zu bauen sind Suchalgorithmen
und ein Webinterface, das Nutzern die eigentliche Suche erlaubt.
Im Spiderkonzept werden Bäume entsprechend bewertet, beispielsweise
als „Spam-Zweig“ (kappt man den, so werden auch viele andere
Spamquellen „gekappt“) oder als „Such-Zweig auf Italienisch“.
Sofern die Blogsuchmaschine monolingual (also beispielsweise englisch)
spidern soll, müssen auch fremdsprachige Blogs ausgeblendet werden.
Die Blogs in der Wunschsprache lassen sich recht einfach über einen
hohen Anteil an Wörtern aus einem passenden Lexikon ermitteln.
Vermeiden muss man auch, dass der Spider „im Kreis läuft“, denn unter
Millionen Blogs im Index solche Kreise zu ermitteln ist von der
Rechenkapazität her problematisch.
Generell wird auch versucht zu ermitteln, welche Teile des Blogs
welche Infos (Archivlink, interne Links, Blogroll) enthalten, und im
Prinzip können aus diesen Strukturen auch semantische
Schlussfolgerungen gezogen werden.
Blogs selbst werden erkannt anhand ihrer typischen URL-Struktur:
Anhand von 30 Regeln werden bisher 80% der Blogs erkannt. RSS als
Indikator zu nehmen hat sich nicht bewährt.
Im Betrieb zieht der Spider 1 GB/Stunde, es empfiehlt sich also ein
Server mit unlimitiertem Traffic. Ein Bloom-Filter
erübrigt es, alle bisher
erfassten URLs im Speicher zu halten, und die Datenfiles werden linear
strukturiert.
Der Visitor ist ähnlich strukturiert wie der Spider. Hier fallen
allerdings 30 GB/h an – wahrscheinlich weil die dafür vorgesehene
Maschine schneller ist. Statt 30 Connections wie beim Spider werden hier
parallel 50 Verbindungen gefahren.
Ein Problem war, dass nach einer halben Million Blogs dem System nach
einiger Zeit die Blogs ausgingen: Die Datenbank umfasst lediglich eine
halbe Million Blogs und … geht davon aus, dass das die halbe Million
‚besten‘ Blogs sind.
Aus den ‚Wer linkt auf wen“-Statistiken lässt sich ableiten, dass die
Long-Tail-Relation in der Tat umgekehrt exponentiell zueinander
verhält: Es gibt weniger und weniger Blogs mit immer mehr und mehr
Links, die auf sie zeigen. Für die Statistiker unter den Lesenden: Bei
einer doppelt logarithmischen Darstellung ergibt sich eine angenäherte
Gerade.
Timo Derstappen hat auf der
Basis von Technorati-Daten ein ähnliches System als Alert-System für PR-Abteilungen gebaut,
deren eigentliches Ziel die Auslösung eines PR-Alarms war, wenn
bestimmte Begriffe ‚peaken‘. Begriffe wurden in von Hand erstellten
Topic-Maps semantisch miteinander verknüpft und können so benutzt
werden, um Texte inhaltlich zu bewerten. Die Hardware-Anforderungen
sind relativ hoch und schwer im Rahmen eines Hobbyprojekts zu
realisieren. Invalides HTML oder RSS und Spamblogs waren auch für
dieses System – das aktuell nirgends installiert ist – ein Problem.
Buchtipp: „Mining the Web – Discovering Knowledge from Hypertext Data“
von S. Chakrabarti